Why would you run PostgreSQL in Kubernetes, and how?
Discover best practices on running PostgreSQL on Kubernetes, from avoiding cloud database lock-ins to maximizing storage and backup efficiency


This is a guest post by Chris Engelbert, Chief Database Solutions Architect and Developer Advocate at Simplyblock.
Running PostgreSQL in Kubernetes
When you need a PostgreSQL service in the cloud, there are two common ways to achieve this. The initial thought is going for one of the many hosted databases, such as Amazon RDS or Aurora, Google’s CloudSQL, Azure Database for Postgres, and others. An alternative way is to self-host a database. Something that was way more common in the past when we talked about virtual machines but got lost towards containerization. Why? Many believe containers (and Kubernetes specifically) aren’t a good fit for running databases. I firmly believe that cloud databases, while seemingly convenient at first sight, aren’t a great way to scale and that the assumed benefits are not what you think they are. Now, let’s explore deeper strategies for running PostgreSQL effectively in Kubernetes.
Many people still think running a database in Kubernetes is a bad idea. To understand their reasoning, I did the only meaningful thing: I asked X (formerly Twitter) why you should not run a database. With the important addition of “asking for a friend.” Never forget that bit. You can thank me later 🤣
The answers were very different. Some expected, some not.
K8s is not designed with Databases in Mind!
When Kubernetes was created, it was designed as an orchestration layer for stateless workloads, such as web servers and stateless microservices. That said, it initially wasn’t intended for workloads like databases or any other workload that needs to hold any state across restarts or migration.
So while this answer had some initial merit, it isn’t true today. People from the DoK (Data on Kubernetes) Community and the SIG Storage (Special Interest Group), which is responsible for the CSI (Container Storage Interface) driver interface, as well as the community as a whole, made a tremendous effort to bring stateful workloads to the Kubernetes world.
Never run Stateful Workloads in Kubernetes!
From my perspective, this one is directly related to the claim that Kubernetes isn’t made for stateful workloads. As mentioned before, this was true in the past. However, these days, it isn’t much of a problem. There are a few things to be careful about, but we’ll discuss some later.
Persistent Data will kill you! Too slow!
When containers became popular in the Linux world, primarily due to the rise of Docker, storage was commonly implemented through overlay filesystems. These filesystems had to do quite the magic to combine the read-only container image with some potential (ephemeral) read-write storage. Doing anything IO-heavy on those filesystems was a pain. I’ve built Embedded Linux kernels inside Docker, and while it was convenient to have the build environment set up automatically, IO speed was awful.
These days, though, the CSI driver interface enables direct mounting of all kinds of storage into the container. Raw blog storage, file storage, FUSE filesystems, and others are readily available and often offer immediate access to functionality such as snapshotting, backups, resizing, and more. We’ll dive a bit deeper into storage later in the blog post.
Nobody understands Kubernetes!
This is my favorite one, especially since I’m all against the claim that Kubernetes is easy. If you never used Kubernetes before, a database isn’t the way to start. Not … at … all. Just don’t do it. If you’re not familiar with Kubernetes, avoid using it for your database.
What’s the Benefit? Databases don’t need Autoscaling!
That one was fascinating. Unfortunately, nobody from this group responded to the question about their commonly administered database size. It would’ve been interesting. Obviously, there are perfect use cases for a database to be scaled—maybe not storage-wise but certainly compute-wise.
The simplest example is an online shop handling the Americas only. It’ll mostly go idle overnight. The database compute could be scaled down close to zero, whereas, during the day, you have to scale it up again.
Databases and Applications should be separated!
I couldn’t agree more. That’s what node groups are for. It probably goes back to the fact that “nobody understands Kubernetes,” so you wouldn’t know about this feature.
Simply speaking, node groups are groups of Kubernetes worker nodes commonly grouped by hardware specifications. You can tag and taint those nodes to specify which workloads are supposed to be run on and by them. This is super useful!
Not another Layer of Indirection / Abstraction!
Last but not least is the abstraction layer argument. And this is undoubtedly a valid one. If everything works, the world couldn’t be better, but if something goes wrong, good luck finding the root cause. And it only worsens the more abstraction you add, such as service meshes or others. Abstraction layers are two sides of the same coin, always.
Why run PostgreSQL in Kubernetes?
If there are so many reasons not to run my database in Kubernetes, why do I still think it’s not only a good idea but should be the standard?
No Vendor Lock-in
First and foremost, I firmly believe that vendor lock-in is dangerous. While many cloud databases offer standard protocols (such as Postgres or MySQL compatible), their internal behavior or implementation isn’t. That means that over time, your application will be bound to a specific database’s behavior, making it an actual migration whenever you need to move your application or, worse, make it cross-cloud or hybrid-compatible.
Kubernetes abstracts away almost all elements of the underlying infrastructure, offering a unified interface. This makes it easy to move workloads and deployments from AWS to Google, from Azure to on-premise, from everywhere to anywhere.
Unified Deployment Architecture
Furthermore, the deployment landscape will look similar—there will be no special handling by cloud providers or hyperscalers. You have an ingress controller, a CSI driver for storage, and the Cert Manager to provide certificates—it’s all the same.
This simplifies development, simplifies deployment, and, ultimately, decreases the time to market for new products or features and the actual development cost.
Automation
Last, the most crucial factor is that Kubernetes is an orchestration platform. As such, it is all about automating deployments, provisioning, operation, and more.
Kubernetes comes with loads of features that simplify daily operations. These include managing the TLS certificates and up- and down-scaling services, ensuring multiple instances are distributed across the Kubernetes cluster as evenly as possible, restarting failed services, and the list could go on forever. Basically, anything you’d build for your infrastructure to make it work with minimal manual intervention, Kubernetes has your back.
Best Practices when running PostgreSQL on Kubernetes
With those things out of the way, we should be ready to understand what we should do to make our Postgres on K8s experience successful.
While many of the following thoughts aren’t exclusively related to running PostgreSQL on Kubernetes, there are often small bits and pieces that we should be aware of or that make our lives easier than implementing them separately.
That said, let’s dive in.
Enable Security Features
Let’s get the elephant out of the room first. Use security. Use it wherever possible, meaning you want TLS encryption between your database server and your services or clients. But that’s not all. If you use a remote or distributed storage technology, make sure all traffic from and to the storage system is also encrypted.
Kubernetes has excellent support for TLS using Cert Manager. It can create self-signed certificates or sign them using existing certificate authorities (either internal or external, such as Let’s Encrypt).
You should also ensure that your stored data is encrypted as much as possible. At least enable data-at-rest encryption. You must make sure that your underlying storage solution supports meaningful encryption options for your business. What I mean by that is that a serverless or shared infrastructure might need an encryption key per mounted volume (for strong isolation between customers). At the same time, a dedicated installation can be much simpler using a single encryption key for the whole machine.
You may also want to consider extended Kubernetes distributions such as Edgeless Systems’ Constellation, which supports fully encrypted memory regions based on support for CPUs and GPUs. It’s probably the highest level of isolation you can get. If you need that level of confidence, here you do. I talked to Moritz from Edgeless Systems in an early episode of my Cloud Commute podcast. You should watch it. It’s really interesting technology!
Backups and Recovery
At conferences, I love to ask the audience questions. One of them is, “Who creates regular backups?” Most commonly, all the room had their hands up. If you add a second question about storing backups off-site (different data center, S3, whatever), about 25% to 30% of the hands already go down. That, in itself, is bad enough.
Adding a third question on regularly testing their backups by playing them back, most hands are down. It always hurts my soul. We all know we should do it, but testing backups at a regular cadence isn’t easy. Let’s face it: It’s tough to restore a backup, especially if it requires multiple systems to be restored in tandem.
Kubernetes can make this process less painful. When I was at my own startup just a few years ago, we tested our backups once a week. You’d say this is extensive? Maybe it was, but it was pretty painless to do. In our case, we specifically restored our PostgreSQL + Timescale database. For the day-to-day operations, we used a 3-node Postgres cluster: one primary and two replicas.
Running a Backup-Restore every week, thanks to Kubernetes
Every week (no, not Fridays 🤣), we kicked off a third replica. Patroni (an HA manager for Postgres) managed the cluster and restored the last full backup. Afterward, it would replay as much of the Write-Ahead Log (WAL) as is available on our Minio/S3 bucket and have the new replica join the cluster. Now here was the exciting part, would the node be able to join, replay the remaining WAL, and become a full-blown cluster member? If yes, the world was all happy. If not, we’d stop everything else and try to figure out what happened. Let me add that it didn’t fail very often, but we always had a good feeling that the backup worked.
The story above contains one more interesting bit. It uses continuous backups, sometimes also referred to as point-in-time recovery (PITR). If your database supports it (PostgreSQL does), make use of it! If not, a solution like simplyblock may be of help. Simplyblock implements PITR on a block storage level, meaning that it supports all applications on top that implement a consistent write pattern (which are hopefully all databases).
Don’t roll your own Backup Tool
Finally, use existing and tested backup tools. Do not roll your own. You want your backup tool to be industry-proven. A backup is one of the most critical elements of your setup, so don’t take it lightly. Or do you just have anybody build your house?
However, when you have to backup and restore multiple databases or stateful services at once for a consistent but split data set, you need to look into a solution that is more than just a database backup. In this case, simplyblock may be a good solution. Simplyblock can snapshot and backup multiple logical volumes at the same time, creating a consistent view of the world at that point in time and enabling a consistent restore across all services.
Do you use Extensions?
While not all databases are as extensible as PostgreSQL, quite a few have an extension mechanism.
If you need extensions that aren’t part of the standard database container images, remember that you have to build your own image layers. Depending on your company, that can be a challenge. Many companies want signed and certified container images, sometimes for regulatory reasons.
If you have that need, talk to whoever is responsible for compliance (SOC2, PCI DSS, ISO 27000 series, …) as early as possible. You’ll need the time. Compliance is crucial but also a complication for us as engineers or DevOps folks.
In general, I’d recommend that you try to stay with the default images as long as possible. Maybe your database has the option to side-load extensions from volume mounts. That way, you can get extensions validated and certified independently of the actual database image.
For PostgreSQL specifically, OnGres’ StackGres has a magic solution that spins up virtual image layers at runtime. They work on this technology independently from StackGres, so we might see this idea come to other solutions as well.
Think about Updates of your PostgreSQL and Kubernetes
Updates and upgrades are one of the most hated topics around. We all have been in a situation where an update went off the rails or failed in more than one way. Still, they are crucial.
Sometimes, updates bring new features that we need, and sometimes, they bring performance improvement, but they’ll always bring bug fixes. Just because our database isn’t publicly accessible (it isn’t, is it? 🤨) doesn’t mean we don’t have to ensure that essential updates (often critical security bug fixes) are applied. If you don’t believe me, you’d be surprised by how many data breaches or cyber-attacks come from employees. And I’m not talking about accidental leaks or social engineering.
Depending on your database, Kubernetes will not make your life easier. This is especially true for PostgreSQL whenever you have to run pg_upgrade. For those not deep into PG, pg_upgrade will upgrade the database data files from one Postgres version to another. For that to happen, it needs the current and the new Postgres installation, as well as double the storage since it’s not an in-place upgrade but rather a copy-everything-to-the-new-place upgrade.
While not every Postgres update requires you to run pg_upgrade, the ones that do hurt a lot. I bet there are similar issues with other databases.
The development cycles of Kubernetes are fast. It is a fast-moving target that adds new functionality, promotes functionality, and deprecates or changes functionality while still in Alpha or Beta. That’s why many cloud providers and hyperscalers only support the last 3 to 5 versions “for free.” Some providers, e.g., AWS, have implemented an extended support scheme that provides an additional 12 months of support for older Kubernetes versions for only six times the price. For that price difference, maybe hire someone to ensure that your clusters are updated.
Find the right Storage Provider
When you think back to the beginning of the blog post, people were arguing that Kubernetes isn’t made for stateful workloads and that storage is slow.
To prove them wrong, select a storage provider (with a CSI driver) that best fits your needs. Databases love high IOPS and low latency, at least most of them. Hence, you should run benchmarks with your data set, your specific data access patterns and queries, and your storage provider of choice.
Try snapshotting and rolling back (if supported), try taking a backup and restoring it, try resizing and re-attaching, try a failover, and measure how long the volume will be blocked before you can re-attach it to another container. All of these elements aren’t even about speed, but your Recovery Point Objective (RPO) and Recovery Time Objective (RTO). They need to fit your requirements. If they exceed them, that’s awesome, but if you find out you’ll have to breach them due to your storage solution, you’re in a bad spot. Migrations aren’t always fun, and I mean, never.
Last but not least, consider how the data is stored. Remember to check for data-at-rest encryption options. Potentially, you’ll need cross-data center or cross-availability zone replication. There are many things to think about upfront. Know your requirements.
How to find the best Storage Provider?
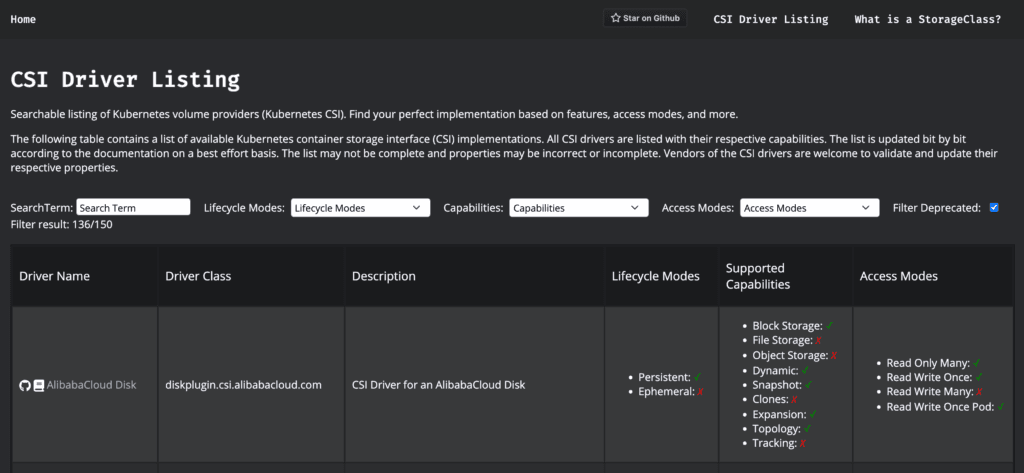
To help select a meaningful Kubernetes storage provider, I created a tool available at https://storageclass.info/csidrivers. It is an extensive collection of CSI driver implementations searchable by features and characteristics. The list contains over 150 providers. If you see any mistakes, please feel free to open a pull request. Most of the data is extracted manually by looking at the source code.
Requests, Limits, and Quotas
This one is important for any containerization solution. Most databases are designed with the belief that they can utilize all resources available, and so is PostgreSQL.
That should be the case for any database with a good amount of load. I’d always recommend having your central databases run on their own worker nodes, meaning that apart from the database and the essential Kubernetes services, nothing else should be running on the node. Give the database the freedom to do its job.
If you run multiple smaller databases, for example, a shared hosting environment or free tier service, sharing Kubernetes worker nodes is most probably fine. In this case, make sure you set the requests, limits, and quotas correctly. Feel free to overcommit, but keep the noise neighbor problem at the back of your head when designing the overcommitment.
Apart from that, there isn’t much to say, and a full explanation of how to configure these is out of the scope of this blog post. There is, however, a great beginner write-up by Ashen Gunawardena on Kubernetes resource configuration.
One side note, though, is that most databases (including PostgreSQL) love huge pages. Remember that huge pages must be enabled twice on the host operating system (and I recommend reserving memory to get a large continuous chunk) and in the database deployment descriptor. Again, Nickolay Ihalainen already has an excellent write-up. While this article is about Huge Pages with Kubernetes and PostgreSQL, much of the basics are the same for other databases, too.
Make your Database Resilient
One of the main reasons to run your database in the cloud is increased availability and the chance to scale up and down according to your current needs.
Many databases provide tools for high availability with their distributions. For others, it is part of their ecosystems, just as it is for PostgreSQL. Like with backup tools, I’d strongly discourage you from building your own cluster manager. If you feel like you have to, collect a good list of reasons. Do not just jump in. High availability is one of the key features. We don’t want it to fail.
Another resiliency consideration is automatic failover. What happens when a node in my database cluster dies? How will my client failover to a new primary or the newly elected leader?
For PostgreSQL you want to look at the “obvious choices” such as Patroni, repmgr, pg_auto_failover. There are more, but those seem to the ones to use with Patroni most probably leading the pack.
Connection Pool: Proxying Database Connections
In most cases, a database proxy will transparently handle those issues for your application. They typically handle features such as retrying and transparent failover. In addition, they often handle load balancing (if the database supports it).
This most commonly works by the proxy accepting and terminating the database connection, which itself has a set of open connections to the underlying database nodes. Now the proxy will forward the query to one of the database instances (in case of primary-secondary database setups, it’ll also make sure to send mutating operations to the primary database), wait for the result, and return it. If an operation fails because the underlying database instance is gone, the proxy can retry it against a new leader or other instance.
In PostgreSQL, you want to look into tools such as PgBouncer, PgPool-II, and PgCat, with PgBouncer being the most famous choice.
Observability and Monitoring
In the beginning, we established the idea that additional abstraction doesn’t always make things easier. Especially if something goes wrong, more abstraction layers make it harder to get to the bottom of the problem.
That is why I strongly recommend using an observability tool, not just a monitoring tool. There are a bunch of great observability tools available. Some of them are DataDog, Instana, DynaTrace, Grafana, Sumologic, Dash0 (from the original creators of Instana), and many more. Make sure they support your application stack and database stack as wholeheartedly as possible.
A great observability tool that understands the layers and can trace through them is priceless when something goes wrong. They often help to pinpoint the actual root cause and help understand how applications, services, databases, and abstraction layers work together.
Use a Kubernetes Operator
Ok, that was a lot, and I promise we’re almost done. So far, you might wonder how I can claim that any of this is easier than just running bare-metal or on virtual machines. That’s where Kubernetes Operators enter the stage.
Kubernetes Operators are active components inside your Kubernetes environment that deploy, monitor, and operate your database (or other service) for you. They ask for your specifications, like “give me a 3-node PostgreSQL cluster” and set it all up. Usually, including high availability, backup, failover, connection proxy, security, storage, and whatnot.
Operators make your life easy. Think of them as your database operations person or administrator.
For most databases, one or more Kubernetes Operators are available. I’ve written about how to select a PostgreSQL Kubernetes Operator for your setup. You can read about them here. For other databases, look at their official documentation or search the Operator Hub.
Anyhow, if you run a database in Kubernetes, make sure you have an Operator at hand. Running a database is more complicated than the initial deployment. I’d even claim that day-to-day operations are more important than deployment.
Actually, for PostgreSQL (and other databases will follow), the Data on Kubernetes Community started a project to create a comparable feature list of PostgreSQL Kubernetes Operators. So far, there isn’t a searchable website yet (as for storage providers), but maybe somebody wants to take that on.
PostgreSQL in Kubernetes is not Cloud SQL
If you read to this point, thank you and congratulations. I know there is a lot of stuff here, but I doubt it’s actually complete. I bet if I’d dig deeper, I would find many more pieces to the game.
As I mentioned before, I strongly believe that if you have Kubernetes experience, your initial thought should be to run your database on Kubernetes, taking in all of the benefits of automation, orchestration, and operation.
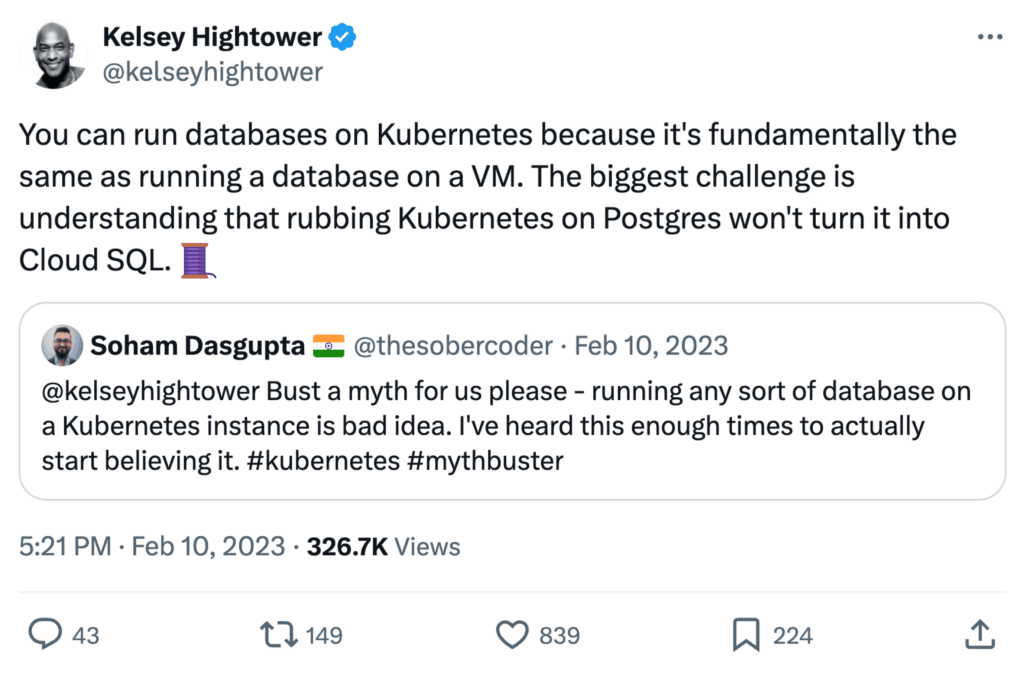
One thing we shouldn’t forget, though, running a Postgres on Kubernetes won’t turn it into Cloud SQL, as Kelsey Hightower once said. However, using a cloud database will also not free you of the burden of understanding query patterns, cleaning up the database, configuring the correct indexes, or all the other elements of managing a database. They literally only take away the operations, and here you have to trust they do the right thing.